Exam 3: Advanced Scheming
Assigned: Monday, 1 December 2008
Due: Beginning of class, Friday, 5 December 2008
Preliminaries
Exam format
This is a take-home examination. You may use any time or times you deem appropriate to complete the exam, provided you return it to me by the due date.
There are 10 problems, each worth 10 points for a total of 100 points. Although each problem is worth the same amount, problems are not necessarily of equal difficulty.
Read the entire exam before you begin.
I expect that someone who has mastered the material and works at a moderate rate should have little trouble completing the exam in a reasonable amount of time. In particular, this exam is likely to take you about two to three hours, depending on how well you've learned the topics and how fast you work. You should not work more than four hours on this exam. Stop at four hours and write “There's more to life than CS” and you will earn at least 75 points on this exam.
I would also appreciate it if you would write down the amount of time each problem takes. Each person who does so will earn two points of extra credit. Since I worry about the amount of time my exams take, I will give two points of extra credit to the first two people who honestly report that they've spent at least three hours on the exam or completed the exam. (At that point, I may then change the exam.)
Academic honesty
This examination is open book, open notes, open mind, open computer, open Web. However, it is closed person. That means you should not talk to other people about the exam. Other than as restricted by that limitation, you should feel free to use all reasonable resources available to you.
As always, you are expected to turn in your own work. If you find ideas in a book or on the Web, be sure to cite them appropriately. If you use code that you wrote for a previous lab or homework, cite that lab or homework and the other members of your group.
Although you may use the Web for this exam, you may not post your answers to this examination on the Web. And, in case it's not clear, you may not ask others (in person, via email, via IM, by posting a please help message, or in any other way) to put answers on the Web.
Because different students may be taking the exam at different times, you are not permitted to discuss the exam with anyone until after I have returned it. If you must say something about the exam, you are allowed to say “This is among the hardest exams I have ever taken. If you don't start it early, you will have no chance of finishing the exam.” You may also summarize these policies. You may not tell other students which problems you've finished. You may not tell other students how long you've spent on the exam.
You must include both of the following statements on the cover sheet of the examination.
- I have neither received nor given inappropriate assistance on this examination.
- I am not aware of any other students who have given or received inappropriate assistance on this examination.
Please sign and date each statement. Note that the statements must be true; if you are unable to sign either statement, please talk to me at your earliest convenience. You need not reveal the particulars of the dishonesty, simply that it happened. Note also that inappropriate assistance is assistance from (or to) anyone other than Professor Weinman (that's me) or Professor Davis.
Presenting Your Work
You must present your exam to me in two forms: both physically and electronically. That is, you must write all of your answers using the computer, print them out, number the pages, put your name on the top of every page, and hand me the printed copy. You must also email me a copy of your exam. You should create the emailed version by copying the various parts of your exam and pasting them into an email message. In both cases, you should put your answers in the same order as the problems. Failure to name and number the printed pages will lead to a penalty of two points. Failure to turn in both versions may lead to a much worse penalty.
In many problems, I ask you to write code. Unless I specify otherwise in a problem, you should write working code and include examples that show that you've tested the code. Do not include images; I should be able to regenerate those.
Unless I explicitly ask you to document your procedures, you need not write introductory comments.
Just as you should be careful and precise when you write code and documentation, so should you be careful and precise when you write prose. Please check your spelling and grammar. Since I should be equally careful, the whole class will receive one point of extra credit for each error in spelling or grammar you identify on this exam. I will limit that form of extra credit to five points.
I will give partial credit for partially correct answers. I am best able to give such partial credit if you include a clear set of work that shows how you derived your answer. You ensure the best possible grade for yourself by clearly indicating what part of your answer is work and what part is your final answer.
Getting Help
I may not be available at the time you take the exam. If you feel that a question is badly worded or impossible to answer, note the problem you have observed and attempt to reword the question in such a way that it is answerable. If it's a reasonable hour (before 9 p.m. and after 8 a.m.), feel free to try to call me in the office (269-9812) or at home (xxx-xxxx).
I will also reserve time at the start of classes next week to discuss any general questions you have on the exam.
Problems
Part A: Data Structures and Higher-Order Procedures
Problem 1: Folding Lists
Topics: List recursion, higher-order procedures, encapsulating control.
As you may recall, we began our investigation of recursion by considering how we might step through a list of numbers, adding them (or multiplying them or ...). Here are variants of the two versions we wrote:
One uses simple recursion.
(define sum-right
(lambda (numbers)
(if (null? numbers)
0
(+ (car numbers) (sum-right (cdr numbers))))))
The other uses a helper to accumulate the results.
(define sum-left
(lambda (numbers)
(let kernel ((so-far 0)
(remaining numbers))
(if (null? remaining)
so-far
(kernel (+ so-far (car remaining))
(cdr remaining))))))
If you think carefully about it, the two processes compute results
slightly differently. Given the list (n0 n1 n2 n3 n4),
the first computes
(+ n0 (+ n1 (+ n2 (+ n3 n4))))
while the second computes
(+ (+ (+ (+ n0 n1) n2) n3) n4)
For addition, this doesn't make a difference. If the operation were subtraction, it would certainly make a difference.
The process of combining a list of values using a binary procedure
is quite common. We've seen it for addition, subtraction, and
multiplication.
We might also use it for appending strings and many other operations.
Computer scientists have various names for such a process. We'll call
it fold, but others use inject
(as in “inject this
operation into this list”)
or reduce (as in, “reduce this list to a
single value”).
(a) fold-right
Write a procedure, ( that mimics
fold-right
proc lst)sum-right, but with proc in place of
+. That is,
(fold-right should compute
proc (list v0 v1 v2 ... vn-1 vn))
(proc v0 (proc v1 (proc v2 (... (proc vn-1 vn) ... ))))
For example,
>(fold-right + (list 1 2 3 4))10>(fold-right * (list 1 2 3 4))24>(fold-right - (list 1 2 3 4))-2>(fold-right (lambda (s1 s2) (string-append s1 ", " s2)) (list "sentient" "malicious" "powerful" "stupid"))"sentient, malicious, powerful, stupid">(fold-right list (list 'a 'b 'c 'd 'e))(a (b (c (d e))))
Hint:
Note that there is an important difference between these examples and what
sum-right does.
sum-right returns 0 for its base case because 0 is
the additive identity.
What is the identity for proc, an arbitrary binary
procedure?
We don't know.
Instead of returning 0 in the base case,
fold-right will need to return the right-most item
in the list.
(b) fold-left
Write a procedure, ( that mimics
fold-left
proc lst)sum-left, but with proc in place of
+. That is,
(fold-left should compute
proc (list v0 v1 v2 ... vn-1 vn))
(proc (proc ... (proc (proc v0 v1) v2) ... vn-1) vn)
For example,
>(fold-left + (list 1 2 3 4))10>(fold-left * (list 1 2 3 4))24>(fold-left - (list 1 2 3 4))-8>(fold-left (lambda (s1 s2) (string-append s1 ", " s2)) (list "sentient" "malicious" "powerful" "stupid"))"sentient, malicious, powerful, stupid">(fold-left list (list 'a 'b 'c 'd 'e))((((a b) c) d) e)
Hint:
Note that there is an important difference between these examples and
what
sum-left does.
sum-left initializes so-far
to 0 because 0 is
the additive identity.
What is the identity for proc, an arbitrary binary
procedure?
We don't know.
Instead of initializing so-far to 0,
fold-left will need to initialize
so-far to the left-most value in the list. (Why?)
Problem 2: Transforming Vectors
Topics: Vectors, numeric recursion, high-order procedures.
We've seen how to implement map using recursion
over lists.
But we might also want to apply a procedure to each item in a vector.
Write a procedure, (, that
replaces each value in vector-transform!
vec proc)vec with the result of
applying proc to that value. For example,
>(define vec-nums (vector 1 2 3 4 5))vec-nums>(vector-transform! vec-nums (l-s + 1))#(2 3 4 5 6)>(vector-transform! vec-nums (l-s expt 2))#(4 8 16 32 64)>vec-nums#(4 8 16 32 64)
Problem 3: Checking Trees
Topics: Deep recursion, pair structures, predicates.
You have seen the predicate number-tree? that
determines whether every leaf in a tree is a number. Generalize this
idea by writing the predicate
(tree-all?
pred? tree),
which indicates whether the predicate pred? is
satisfied for all leaves in tree.
For example,
>(tree-all? number? (cons (cons (cons 1 2) (cons 3 4)) (cons 5 (cons 6 7))))#t>(tree-all? even? (cons (cons (cons 1 2) (cons 3 4)) (cons 5 (cons 6 7))))#f>(tree-all? char? (cons (cons #\a #\b) #\c))#t>(tree-all? char? (cons (cons #\a #\b) "c"))#f>(tree-all? odd? 1)#t>(tree-all? char? 1)#f
Problem 4: Searching Files
Topics: Higher-order procedures, searching, files.
Write, but do not document, a procedure,
(, that searches the specified file
for the first value that matches file-search filename
pred?)pred?. For
example, if the file contains the values
12 1 23 152 6
then we might see the following results.
>(file-search "sample-file" odd?)1>(file-search "sample-file" (lambda (x) (> x 100)))152>(file-search "sample-file" (lambda (x) (< x 0)))#f>(file-search "sample-file" string?)#f
Problem 5: Mystery Procedure
Topics: Pair structures, deep recursion, reading code.
The following procedure does something with trees.
(define puzzle
(lambda (tt)
(if (pair? tt)
(+ 1 (puzzle (car tt)) (puzzle (cdr tt)))
0)))
Explain the purpose of this procedure. That is, explain what the procedure computes, not how it does that computation.
Part B: Writing Code Concisely
Problem 6: Fun with Strings
Topics:
Higher-order programming, map,
sectioning, conciseness.
Fill in the blanks as concisely as possible so that the given
expressions produce the results shown.
(Recall that the procedure char-upcase can be used
to convert lower-case characters to upper-case.)
>(define strings (list "sentient" "malicious" "stupid"))strings>(map _______________________ strings)("Computers are sentient" "Computers are malicious" "Computers are stupid")>(map _______________________ strings)("sentiently" "maliciously" "stupidly")>(list->string (map _______________________ strings))"SMS"
Problem 7: The Log of a Product is the Sum of the Logs
Topics:
Higher-order programming,
map,
apply,
conciseness.
A very useful mathematical identity is the fact that the log of the
product of numbers is equal to the sum of the log of the
numbers. You may have seen the special case for two numbers,
log(a*b) = log(a) + log(b), but this generalizes to any number of values. In the following, you will use the built-in Scheme procedure log.
(a) Log of a product
Assume that numbers is defined as a list of
numbers.
Write a Scheme expression that first computes the product of
numbers
and then takes the log of
that product. (You should not use lambda in your
expression.)
That is, if numbers is defined as
(list 1 2 3 4),
your expression should calculate log(1*2*3*4).
(b) Sum of the logs
Write a Scheme expression that calculates the mathematical
equivalent of the previous expression: first take the log of
each number in the list numbers, and then sum
these log values. (Again, you should not use lambda
in your expression.)
That is, if numbers is defined as
(list 1 2 3 4), your
expression should calculate log(1)+log(2)+log(3)+log(4).
Part C: Testing
Problem 8: Stalking the Elusive Bug
Topics: Unit testing, numeric recursion, strings.
When a procedure passes a series of tests, can you be certain the procedure is implemented correctly? Unfortunately not. Consider the following procedure and test suite.
;;; Procedure:
;;; string-contains?
;;; Parameters:
;;; str, a string
;;; substr, a string
;;; Purpose:
;;; Determine whether substr is contained in str.
;;; Produces:
;;; result, an integer or #f
;;; Preconditions:
;;; No additional.
;;; Postconditions:
;;; If result is #f, then substr is not contained in str.
;;; If result is an integer, then
;;; 0 <= result < (string-length str)
;;; substr appears as a substring of str beginning at position result.
(define string-contains?
(lambda (str substr)
(let ((substr-len (string-length substr)))
(let kernel ((start 0)
(finish (- (string-length str) substr-len)))
(cond ((= start finish)
#f)
((equal? substr (substring str
start
(+ start substr-len)))
start)
(else
(kernel (+ 1 start) finish)))))))
(begin-tests!)
(test! (string-contains? "banana" "ban") 0)
(test! (string-contains? "banana" "nan") 2)
(test! (string-contains? "banana" "NAN") #f)
(test! (string-contains? "banana" "orange") #f)
(end-tests!)
Although the procedure passes the given tests, it is not correctly implemented. In fact, there are at least two different situations in which this procedure gives an incorrect result.
Write two distinct test cases (using test!)
for which the given implementation of
string-contains? fails.
What do we mean by distinct? The relationship between
substr and str
should be different in each case.
As a counterexample, these two tests are not distinct.
They are testing essentially the same thing.
(test! (string-contains? "banana" "ban") 0) (test! (string-contains? "pineapple" "pine") 0)
Do you see why?
Part D: Iterating Over Images
Problem 9: Motion Blur
Topics: Numeric recursion, image iteration, image transformations.
All of the image transformations we have considered so far change each pixel independently of the others by applying a color transformation to each pixel. However, we can certainly imagine image transformation where the new color of each pixel also depends on the color of other pixels nearby.
We can create a motion blur effect on an image using the following algorithm. We visit each pixel in the image, row-by-row and column-by-column, from left to right and top to bottom. If the column is 0 (zero), then the color remains unchanged. Otherwise, we change the color of the pixel at (row, col) to the average of two colors: the current color of that pixel and the color of the pixel immediately to the left.
Write a new procedure, ( that takes an image and applies
this motion-blur effect.
image-motion-blur!
image)
Here's an example using image-motion-blur!.
| Actual size | 5x zoom | |
|
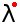 |
 |
|
 |
 |
Hint: You will need a kernel procedure that
recurses over the column and row and manipulates the color data using
image-get-pixel,
image-set-pixel!, and
rgb-average.
Your recursive kernel might also keep
track of the previous color, but it is not absolutely necessary.
Warning: Test your procedure on small images.
Problem 10: Color Histograms
Topics:
Vectors,
color palettes,
image-scan-region.
As you may know, a histogram measures the frequency of occurrence of different types of items in a set. For example, we might survey the class and produce a histogram that gives the number of first-years, second-years, juniors, and seniors, or the number of science, social studies, humanities, and other majors. Machine vision researchers (and others) are sometimes concerned with the frequency at which each color occurs in an image. Since the number of possible colors is so huge, they use a smaller palette to categorize each color in the image. In this problem, we'll use a palette to encode each pixel in an image, and count the number of times each palette index occurs.
Recall the procedure (palette-encode-color
palette color), which
encodes a color by returning the index of the closest color from the
palette.
Recall also that image-scan-region allows us to
iterate over all the pixels in a region of an image.
Use image-scan-region and
palette-encode-color to implement the
procedure documented as follows.
;;; Procedure: ;;; image-palette-histogram ;;; Parameters: ;;; image, an image identifier ;;; palette, a list of RGB colors ;;; Purpose: ;;; To count the number of times each palette-encoded color is used in an image ;;; Produces: ;;; hist, a vector ;;; Preconditions: ;;; palette is non-null ;;; Postconditions: ;;; The length of hist is the same as the length of palette. ;;; Each index in hist contains the number of times the corresponding palette ;;; color is used in the image.
You can copy the palette-encode-color and
related procedures from here. You do not
need to include them in your solution.
Hint:
You will need to create a vector and use it in the body of an
anonymous procedure passed
to image-scan-region.
Each time you encode a color from the image, increment the
value in the vector that corresponds to the resulting index.
Some example runs are below:
>(define colors-rainbow (list color-red color-orange color-yellow color-green color-blue color-indigo color-violet))colors-rainbow>(image-palette-histogram (image-load "/usr/share/pixmaps/fsview.xpm") colors-rainbow)#(0 179 284 42 165 108 246)>(image-palette-histogram (image-load "/usr/share/pixmaps/gnome-error.png") colors-rainbow)#(205 189 23 0 0 0 1887)>(image-palette-histogram (image-load "/usr/share/pixmaps/python.xpm") colors-rainbow)#(0 14 531 0 0 18 958)
Some questions and answers
Question 4
#t or #f appropriately.
Question 6
string-ref. You can find it in the
reference or the reading on strings.
Question 7
log that you can use.Question 8
(string-contains? "banana" "bna")
string-contains? should
return #f.
Question 9
image-motion-blur! should return.
Errata
Here you will find errors of spelling, grammar, and design that students have noted. Remember, each error found corresponds to a point of extra credit for everyone. I usually limit such extra credit to five points. However, if I make an astoundingly large number of errors, then I will provide more extra credit.
- “Concisely” was misspelled as “consisely”. [MRW, 1 point]
-
In Problem 1, there is an important difference between
sum-rightandfold-right, and betweensum-leftandfold-left, that was not noted. [JW & JLND, 1 point] -
Incorrectly referred to
fold-rightrather thanfold-leftin above clarification. [ET, 1 point] -
The documentation for problem 8 referred to
stringrather thanstr. [MRW, 1 point]