Motivation
 |
traditional Asi Hcalipg Arts |
Most commercial OCR systems geared for document recognition cannot handle the wider variety of fonts found in many street scenes and signs, as demonstrated by the example above.
We address this by adding two components to a robust character recognizer trained on many fonts, one that adapts to the specific font in a sign by using character similarity, and another that intelligently incorporates a lexicon without slowing the system. Unlike previous work, all the information sources are unified in a single model for recognizing characters.
Character Similarity
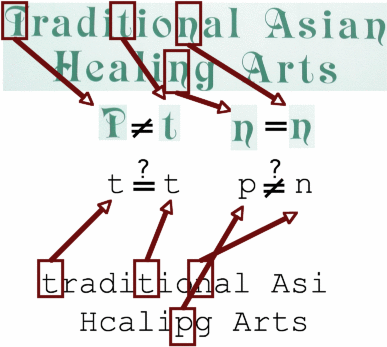
Although many fonts can be quite difficult, there is one bit of information that can be easily incorporated: whether two characters appear the same or not. Regardless of the label that is given, two characters that appear the same should be given the same label, and two characters that appear different should be given different labels.
Earlier work has incorporated this for document recognition, where thousands of example characters available, but in sign recognition only a handful are present.
We begin by learning a simple "similarity" function that identifies whether characters are the same or different, regardless of identity.
Similarity Model
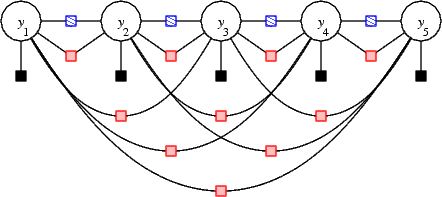
Whereas prior work clustered characters prior to recognition, our unified model uses all the information, including similarity, simultaneously. This prevents unrecoverable errors from a clustering step.
Example Results

Lexicon Incorporation
Using a lexicon can greatly boost recognition rates, but this often comes at the expense of efficiency when the lexicon is large. We have proposed an addition to the model that incorporates the lexicon as a unified part, rather than post processing, without reducing the speed of the system.
By using a sparse inference method, only words with moderate support from the character appearance and local language models become candidates. This is done by using a constrained optimization technique that eliminates as many lexicon words as possible, without deviating too much from the original probability approximation.
Lexicon Model

By introducing an auxiliary variable that indicates whether a particular string is from the lexicon, we can learn a bias for predicting known words. Note that this is integrated with the local language and generic character recognition models.
Thus, appearance is taken into consideration, unlike in postprocessing approaches. We have also joined the lexicon and similarity-based recognition models to further improve performance.
Example Results

|
|

|

|
|
| No Lexicon | USED BOOKI | THOR UP5 | Free crecking | 31 BOLTWOOD |
|---|---|---|---|---|
| Lexicon | USED BOOKS | HOOK UPS | Free checking | 31 BOLTWOOD|
| Forced Lexicon | USED BOOKS | HOOK UPS | Free creaking | SI BENTWOOD |
Using a lexicon corrects many errors. In addition, our model prevents false corrections by allowing the predicted words to be drawn from strings outside the lexicon.
Related Papers
- Improving Recognition of Novel Input with Similarity, with E. Learned-Miller. IEEE Conference on Computer Vision and Pattern Recognition (CVPR) June 2006. [PDF] [bib] [doi]
- Fast Lexicon-Based Scene Text Recognition with Sparse Belief Propagation, with E. Learned-Miller and A. Hanson. Intl. Conference on Document Analysis and Recognition (ICDAR) Sept. 2007. [PDF] [bib] [doi]
- Scene Text Recognition using Similarity and a Lexicon with Sparse Belief Propagation with E. Learned-Miller and A. Hanson. IEEE Transactions on Pattern Analysis and Machine Intelligence (PAMI). 21(10), pp. 1733-1746, Oct. 2009 [PDF] [bib] [doi]
Data
The sign images, and character box annotations used for recognition in these papers are available. If this data is used in a publication, please cite the 2009 PAMI paper above.
- Images (tar.bz2 format; 95 files; 9.9M)
- Character boxes (Matlab .mat format)
- README
The font images used as the basis for training the character recognition algorithms are available. The font size is 100px, and the images are generated in a 128x128 pixel window, all at the same baseline, with no anti-aliasing. Images were generated using the GIMP.
Fonts were restricted to those that had "normal" lowercase and uppercase letters, with no graphics. The characters [A-Za-z0-9] appear in the set letters while all other keyboard (PC104) characters appear in the set symbol. To accomodate the character "/" in a Unix file system, that character in the filename was replaced with the (non-keyboard) character "¬".