Motivation
Object detection and recognition systems, such as face detectors and face recognizers, are often trained separately and operated in a feed-forward fashion. Selecting a small number of features for these tasks is important to prevent over-fitting and reduce computation. However, when a system has such related or sequential tasks, selecting features for these tasks independently may not be optimal.
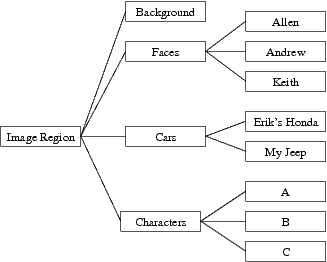
For instance, the figure at right, detection corresponds to finding instances in the middle column, while recognition is finding instances in the rightmost column. Previous work has focused on sharing features for category detection, but not for sub-category recognition.
We propose a framework for choosing features to be shared between detection and recognition tasks. The result is a system that achieves better performance by joint training and is faster because some features for identification have already been computed for detection.
Example Problem
| Characters | Background |

|
|

|
|
| Cars | |
We specifically apply this to the distinct, but highly related problems of text detection and character recognition, simultaneously with car detection and recognition. The detection tasks must only discriminate characters and cars in general from background, while the recognitition task must identify the center character in each window or the particular type of car (e.g., SUV, sedan, van, truck).
Comparison
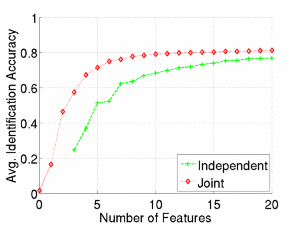
With an independent method, features are selected for the categorization (detection) task and sub-categorization (recognition) separately. In our method, the features are selected jointly and simultaneously for both classifiers. This yields either better performance for the same number of total features used, or faster runtime for the same overall performance.
When features are complex or time-consuming to compute, employing features that are reusable among different system components is highly desirable. This becomes especially important as tasks for vision systems grow in breadth.
Example Results


Related Papers
- Joint Feature Selection for Object Detection and Recognition Technical Report UM-CS-2006-054, University of Massachusetts-Amherst, Amherst, MA 01003-4601, Oct. 2006. [PDF] [bib]
- Updated and expanded results may be found in the PhD thesis, Chapter 5
- Vehicle images for training are taken from the Brown Vehicle Category data set.