Detection Model
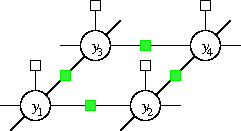
Figure 1. A model for contextual detection. White boxes relate image features to a single unknown label y (sign or background), while green boxes associate image features such as texture gradients with pairs of neighboring labels.
Most previous work has either used (1) a sliding window approach to independently detect individual windows as text (or sign) or (2) an uninformed segmentation method followed by a classification of each region as text versus background.
Our model captures the dependency between neighboring regions and uses powerful texture features to discriminate between signs and uninteresting areas.
Example Results

|


|

|

|
Comparison

|

|

|

|

|

|

|

|
Related Papers
- Sign Detection in Natural Images with Conditional Random Fields, with A. Hanson and A. McCallum. IEEE International Workshop on Machine Learning for Signal Processing (MLSP), pp. 549-558. Sept. 2004 [PS.gz] [PDF] [bib] [doi]
- Preliminary work appears in the above paper. It is greatly expanded in the PhD thesis, chapter 3.
- Publicly available data set (with ground truth) used for training and testing.