Motivation

Markov field models are a common approach to incorporating smoothness constraints for predicting disparity from a pair of stereo images. However, learning the parameters of such models can be slow for larger images because they have potentially large disparities, and most inference algorithms required for learning are linear in the size of the state space (i.e., the number of disparity levels).
Our work proposes modifications to standard learning algorithms that speed the inference process by passing sparse messages. This is accomplished by solving a simple constrained optimization problem that makes messages as sparse as possible while remaining close to the originals. The result is that the updates that incorporate the global smoothness constraints on the disparity drop from being linear in complexity to being highly sub-linear.
Sparsity
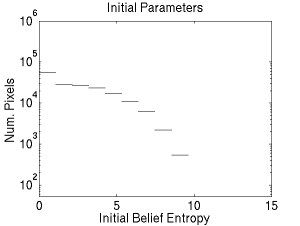
The messages passed in many classes of inference algorithms typically correspond to, or are closely related to, approximate probability distributions, or "beliefs." The key insight is that for many types of models, especially stereo models, most of these beliefs have extremely low probabilities very close to zero. It is precisely these entries in the messages that we want to eliminate, but in a principled fashion.
Rather than impose a limited number of states, or an arbitrary cut-off for probability mass, a divergence criterion is imposed. Thus high entropy messages are kept dense, reflecting their greater uncertainty. However, since most messages are very low entropy, many message entries will be dropped.
Speed Up
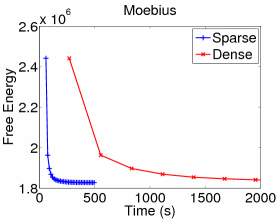
Variational inference techniques such as mean field are common approaches that approximate an intractable probability distribution by choosing a tractable version and minimizing the difference between the original and approximating distribution. This is results in minimizing what is known as a "free energy."
The original method for calculating dense variational updates in our stereo model (which iteratively minimize the free energy), take a great deal of time. Our proposed sparse method reaches the free energy mininima before the dense method completes even one iteration.
Example Results
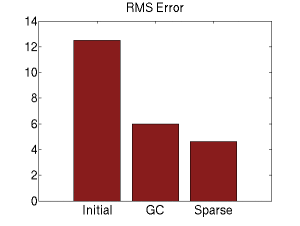
Previous work has used a point estimate during model learning by finding the most likely disparity map using graph cuts. Graph cuts is a very fast algorithm, but this can be problematic for the handful of beliefs with higher entropy, where a point estimate does not reflect the greater uncertainty.
Our approach has the dual advantage of being fast (unlike traditional variational approaches) while also flexibly incorporating the appropriate amount of uncertainty during learning (unlike graph cuts or other point estimates).
The root mean square (RMS) error prediction on test images is lower when learned using our algorithm. Example disparity predictions are also shown here for comparison.
| Graph Cuts | Sparse Variational |
|---|---|
 |
 |
Related Papers
- On Learning Conditional Random Fields for Stereo: Exploring Model Structures and Approximate Inference with C. Pal, L. Tran, and D. Scharstein. International Journal of Computer Vision (IJCV) [PDF] [bib] [doi] The original publication is available at www.springerlink.com
- Efficiently Learning Random Fields for Stereo Vision with Sparse Message Passing with L. Tran and C. Pal. European Conference on Computer Vision (ECCV) October 2008. [PDF] [bib] The original publication is available at www.springerlink.com
- Sparse Message Passing and Efficiently Learning Random Fields for Stereo Vision Technical Report UM-CS-2007-054, University of Massachusetts-Amherst, Amherst, MA 01003-4601, Oct. 2007. [PDF] [bib]
- Stereo images are part of the Middlebury Stereo Data of 2005.
- Code for sparse inference techniques is compatible with the Middlebury Stereo Code and should appear soon.