Motivation

|
Multimodal (text+image) models demonstrate strong object detection performance in both zero-shot and finetuned cases, in part because they replace a limited set of object classes with the natural language descriptions used by people, supporting open-world phrase grounding by learning the associations between words and pixels.
We investigated whether the same approach could apply to smaller-scale object keypoint detection (i.e., for pose estimation), allowing us to use not only part names but also attributes (adjectives) describing those parts.
Overview
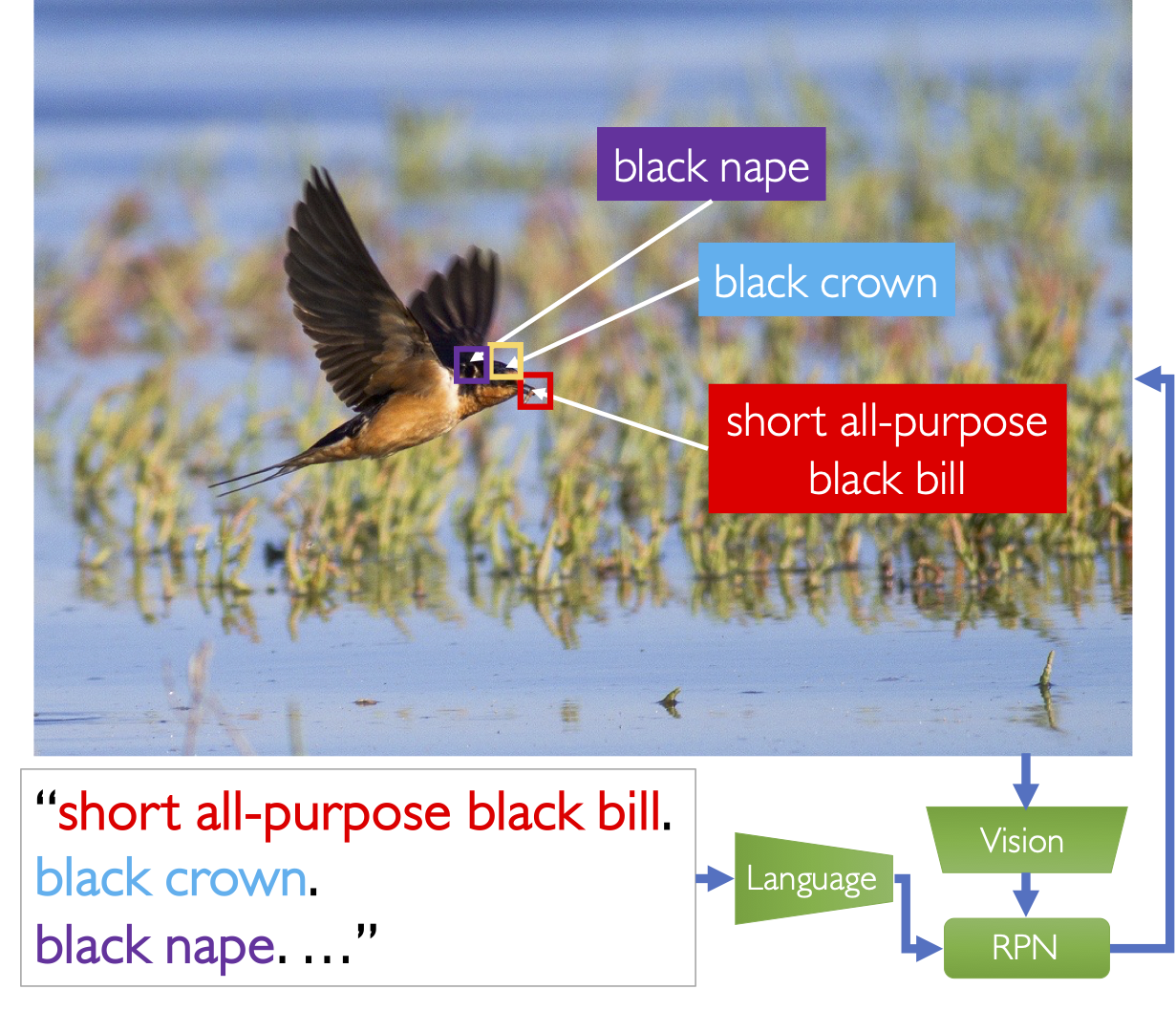
The GLIP model fuses the languistic and visual encodings in an interlinking multilayer head for the region proposal network. Originally designed for phrase grounding, we adapt GLIP to keypoint detection by treating ground truth keypoints as small objects (40×40 pixel boxes).
To evaluate this approach, we train and test on the North American Birds (NABirds) data set, which contains nearly 50,000 images, 400 unique species and annotates eleven bird keypoints for each image.
The captions we ask the model to pinpoint are the common names of each of the eleven keypoints.
However, to test the added value of the language stream, we also evaluate a variant that cuts off semantic contribution by replacing each keypoint label with a single character. This forces the deep fusion layers to rely on the visual characteristics with only a symbol that has no intrinsic meaning.
One strength of multimodal models is the ability to leverage declarative or descriptive attributes for few-shot transfer learning to novel categories. We therefore create a set of richer descriptive attributes for the keypoint query captions, as shown in the Table below.
| Name | Attributes | Examples |
|---|---|---|
| bill | length / shape / color | short all-purpose grey bill. long needle black bill. |
| crown | color | black and white crown. blue crown. |
| nape | color | black and white nape. brown and black nape. buff nape. |
| eye | color | black and red left eye. black right eye. yellow right eye. |
| belly | pattern / color | striped brown and white belly. solid belly. |
| breast | pattern / color | striped yellow and black breast. white breast. |
| back | pattern / color | striped brown black and buff back. solid blue back. |
| tail | pattern / shape / color | solid notched tail. notched brown tail. |
| wing | pattern / shape / color | spotted pointed black and white left wing. |
This work is the first to incorporate such attributes for keypoint detection, rather than whole-image classification or phrase grounding.
The three train/test variants of the data are:
- Symbols
- f. g. h. k. m. n. p. q. r. w. y.
- Names
- bill. crown. nape. left eye. right eye. belly. breast. back. tail. left wing. right wing.
- Names+Attributes
- short cone buff bill. grey crown. grey nape. ..
Evaluation
Both our system and our evaluation combines elements of object and keypoint detection. We note that unlike traditional keypoint detection metrics, our system can learn not to ground a keypoint caption label. Both PCK (percentage of keypoint correct) and the COCO OKS (object keypoint similarity) ignore false positives for keypoints that are not visible. These measures can be misleading in scenarios where keypoint visibility is unknown yet false positives should be minimized (for instance, when the labeled keypoints are to be used in teaching people).
To remedy these shortcomings, we adapt an anisotropic version of the the COCO OKS measure, using the score in the COCO object detection framework by replacing IOU with our OKS calculation so that
- false positive predictions are penalized, and
- distance sensitivity thresholds are swept with the mean average precision calculation.
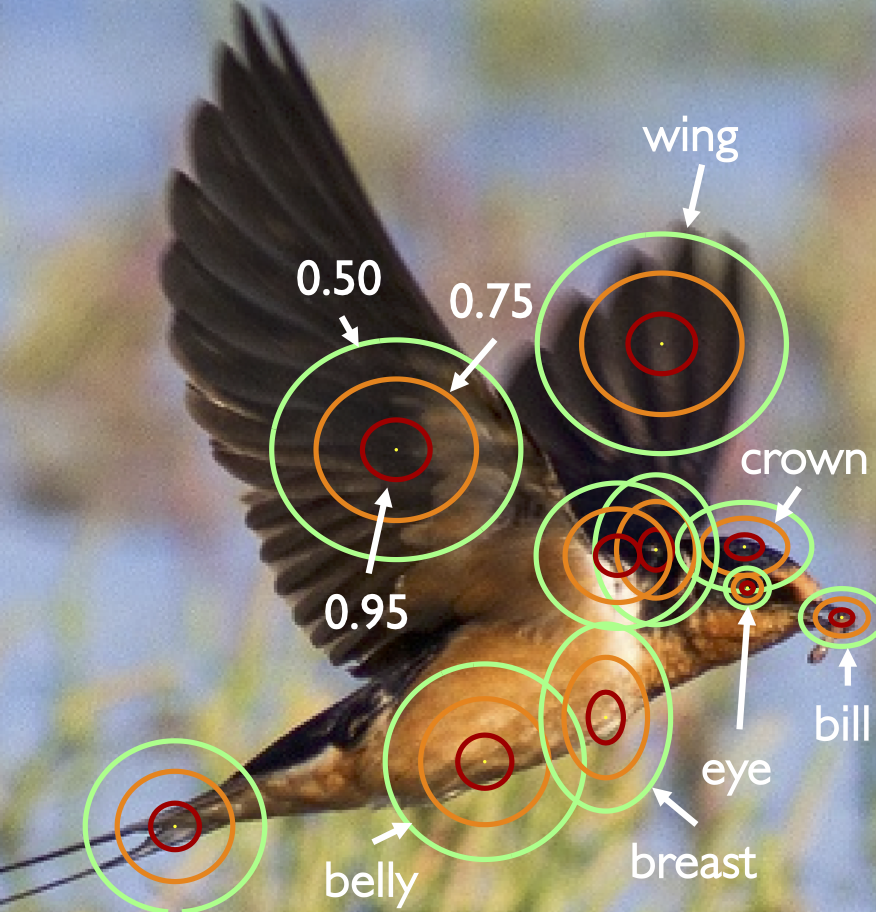
The range of Object Keypoint Similarity (OKS) values used for sweeping mean Average Precision (mAP) are shown here in Figure 3. Note the anisotropy of the breast and crown, while the bill and eye are far more stringent (having smaller rings) than the belly and wings.
Results
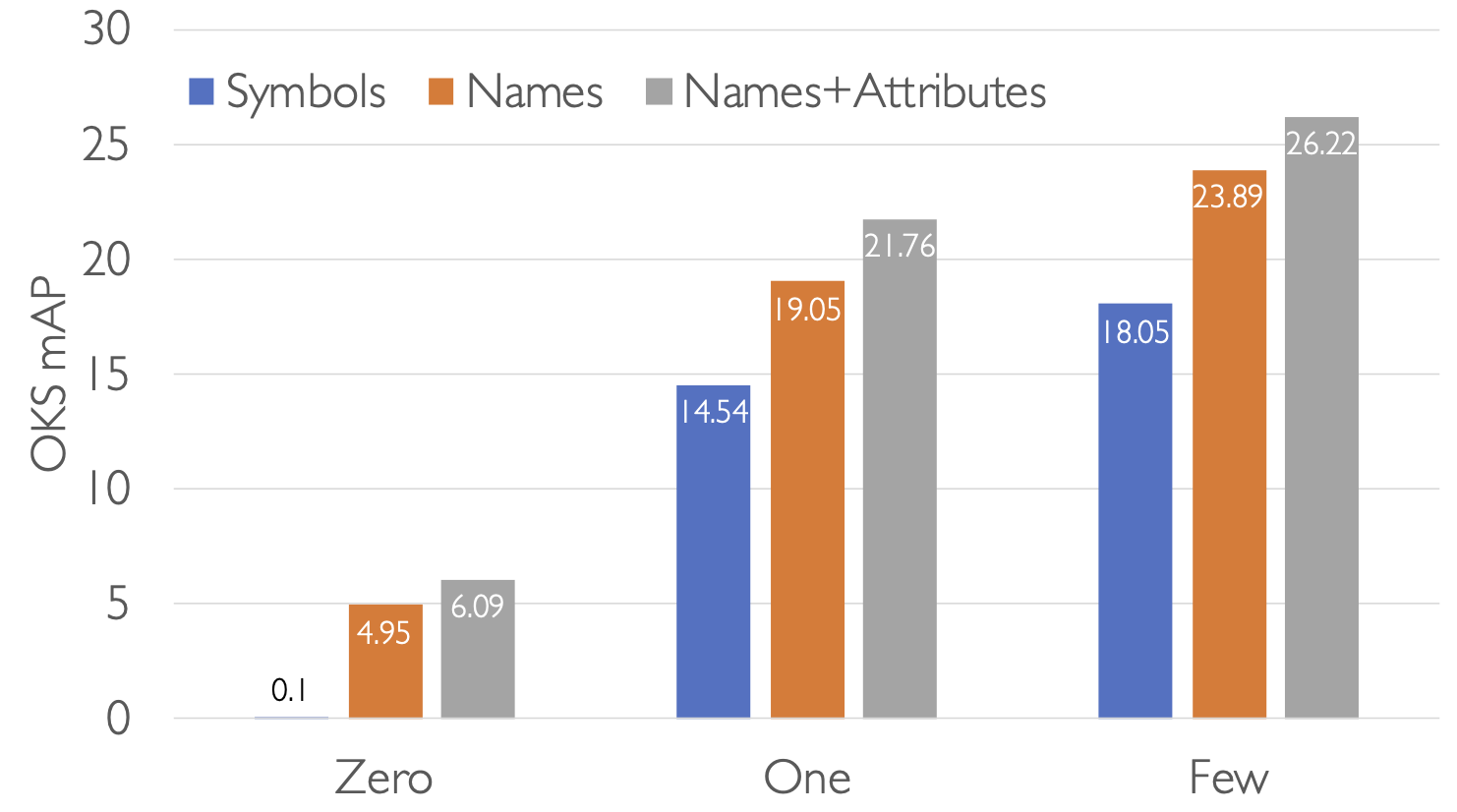
Using only the pretrained GLIP weights, the keypoint names provide low, but measurably better results than meaningless symbols in a zero-shot test scenario.
With one-shot learning, the absolute results improve with the use of part names, though the relative benefit of names remains roughly the same. With ten examples of each part in few shot learning, results continue to improve and the gap widens.
In all the limited learning scenarios, including attributes adds a 1 to 2 point AP boost over names alone.
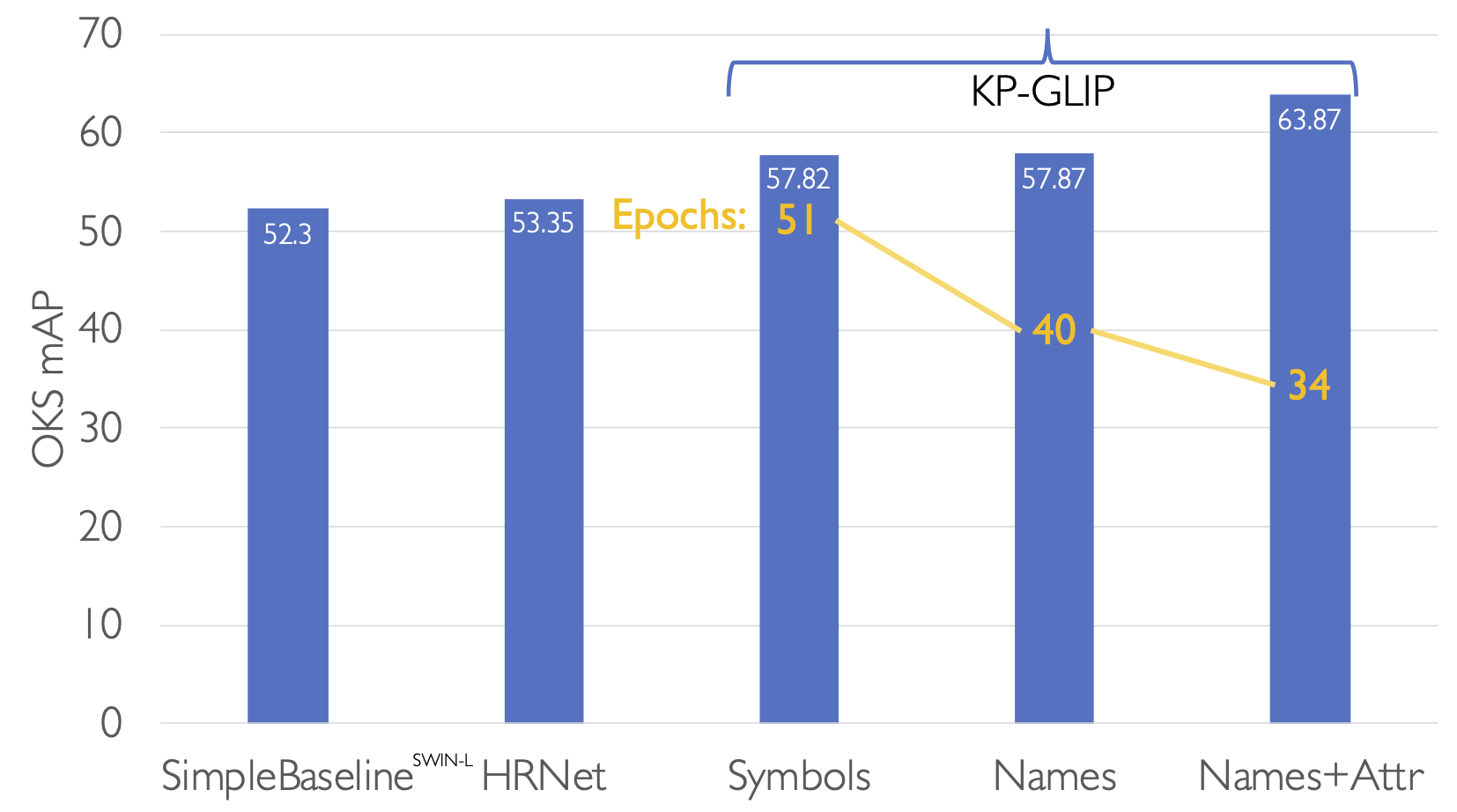
After training to convergence, the KP-GLIP model outperforms earlier heatmap-based approaches, even with the same vision backbone.
Using the keypoint names performs better than the unsemantic symbols, but only marginally. Adding the descriptions to the keypoint names raises the performance a full six points.
Thus, adding descriptive attributes to keypoint names improves performance significantly. But there is an equally important hidden story, which is the time to train. Finetuning the symbolic model, which ignores linguistic cues, takes 51 epochs to converge. However, using the keypoint names takes 20% less time. What’s more, the richer descriptive attributes reduce train time another 15%.
Related Paper
Experimental Data+Code
If this data or code is used in a publication, please cite the appropriate paper above.
Complete Annotations
The annotations with descriptive attributes used in the ICVS 2023 paper are available. Note: These are only the COCO-style annotation files; the original images from NABirds must be acquired separately.
- Annotations (JSON files)
Experimental Code
This repository contains the modifications to GLIPv1 that are used in the ICVS 2023 paper.
- github:weinman/GLIP
- Finetune Attribute Model checkpoints from paper
Contributors
- Co-Investigators:
- Serge Belongie (Pioneer Center for AI/DIKU), Stella Frank (Pioneer Center for AI/DIKU), and Jerod Weinman